


Finding similar-looking images, fast.

Jan 18, 2024
I love a good programming challenge. Especially when it has to do with pixels — preferably lots of them.
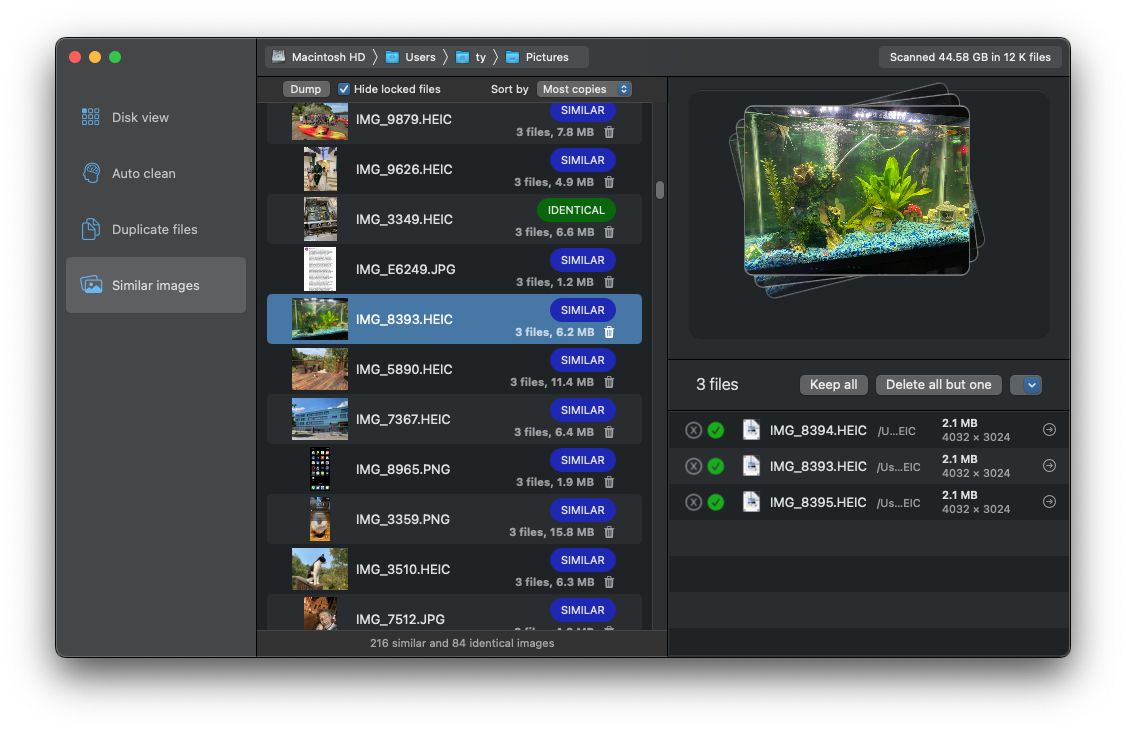
I wanted HyperDisk to include a really solid similar images detector. By solid I mean fast, reliable, and scalable for large image libraries. This presents a serious programming task, made even deeper because it requires some form of “fuzzy logic” — that is to say, logic that’s wishy-washy in how it applies rules and values.
After all, finding identical images is one thing. Finding ones that look similar is a harder problem entirely.
It’s easy for humans to tell when images look similar. But how?
Computers are pure logic and math, which makes them very good at pixels. To computers, an “image” is just a long list of numbers, packed into a rectangle in reading direction (left-to-right, top-to-bottom.) A human-easy task like finding an oval inside an image is a real challenge for a computer. Computers don’t naturally see things in 2D or 3D like we do. It’s just arrays of numbers.
Human vision, at its core, is totally different from computer graphics. Our brains are the original neural network, processing information in analog, seamlessly across dimensions. We see shapes and forms, not pixels and lines. Getting a computer to “see” in this manner is no small task.

Teach the computer to think like a human.
I received some good advice years ago from an executive at a company where I worked. He was a computer programmer by trade, and he told new hires a good conceptual technique for programming. He said we should break apart a problem by thinking about how a smart human might go about doing the problem, and to make the computer do it in a similar way.
As an example, consider a laptop computer that wants to auto-join WiFi when you open it up. A naïve implementation might scan for a list of WiFi networks in the area and try joining each one in succession. If a person were tasked with this job and they did it this way, they could be criticized for being terribly inefficient. A better way would be to keep track of any WiFis you've successfully joined recently, maybe keep track of which ones work best, and try to join those first. In this scenario, a bit of human intuition applied to computer code produces a measurable speed boost.
To find similar images, a human might start with some sorting.
Imagine you're in a room with 54394583904 photos strewn all over the floor. Your job is to group all the ones that look similar. It might make sense to start moving them into areas of the floor. Light images in one area, dark images in another. Reddish ones here, bluish ones over there, etc. This reduces your workload by a good deal, since you've now got fewer images to compare.
The computer can do something similar. The first thing HyperDisk does is to look at the average colors of all the photos it’s trying to compare. It then sorts them based on their predominant color. This information is used later as a sort of pre-filter for image comparison.

A human might defocus their eyes a bit.
If you’ve got a huge number of images to look at and compare, you might want to first glance at them from a distance, sort of scanning them with defocused eyes as opposed to inspecting them closely for detail.
A computer can achieve this ”defocused eyes“ effect by either blurring an image or by drawing it at a reduced size. The second option is usually a lot faster. HyperDisk takes all your images and draws them into tiny little 3x3 pixel tiles inside a big mosaic. This technique is known in programming as an image atlas. HyperDisk looks at the tiles in this atlas and compares the images’ 9 pixels against other images. Because we’ve made the tiles so small, we have a low number of pixels to work with and we can run fast.

Blending images together to find similarity.
HyperDisk treats the results of the 3x3 pixel atlas scan as a preliminary hit-list of potentially similar images. It then builds an atlas of bigger images (somewhere around 15x15 or 20x20 pixels) and compares those. This becomes the list of similar image candidates.
The next step is to find out how similar or different the images actually are. For this, we use an image blending mode known as Difference to find the amount of difference between candidate images. This blend mode takes the pixels from two different images, subtracts their numeric color values, and renders the absolute value of that difference. With this approach, identical images show a difference image of pure black. Similar images will be overall more dark, and very different images will be lighter.

Unleashing the computing power of the GPU.
I was pretty happy with the similar images finder after getting it all programmed and testing it out on image libraries. I optimized it to use all the available CPU cores, and it was faster than most comparable apps I tested. Still, all this code was regular CPU code, and I knew that deep within the heart of a modern computer is a monstrously powerful GPU just waiting to be tapped.
The Graphics Processing Unit is a specialized graphics chip built into just about every computer and phone sold today. A GPU can run thousands of operations at the same time, whereas a CPU can only run 4-8 or so. The caveat is that GPUs are hard to program, and they are only designed for certain tasks. Operating on lots of pixels happens to be right in the GPU’s wheelhouse, so I knew I should try to get some of this image comparison code running on the GPU.
You don’t program a GPU using normal languages like C, Swift, Java, Python etc. You use some form of a “shader language,” a name derived from the traditional application of the technology for shading drawn 3D surfaces. OpenGL and Vulkan are platform-independent GPU languages, DirectX is Microsoft’s, and Metal is Apple’s. Being a Mac app, Metal was the clear choice.

Teaching the GPU to do some of the heavy lifting
GPUs like to be given a large chunk of data, and then get to work on it. They don’t like a lot of back-and-forth, where you’re feeding it bits of data at a time. That kind of work is meant for the CPU. So instead of writing the image compare image-by-image, I needed to give the GPU lots of image data. Once again, atlases were the way.
The image atlases described earlier were a great match for the GPU’s capabilities. By sending large atlases containing thousands of images to the GPU, we used custom shaders to tile candidate images and compare them to each other using Difference blending.
The GPU work wasn’t easy but it produced some big speed gains. I didn’t do formal tests against earlier CPU-based versions of the algorithm, but speeds increased in the neighborhood of 10x.
The end result
A lot of the work that went into this tool was pure experimentation, so it was a big relief when I found out how well it actually worked. We’re planning on doing some semi-official tests and benchmarks against other tools, but suffice it to say HyperDisk blows most of the competition out of the water both in terms of speed and accuracy. We find more matches, in far less time, than Apple’s own similar image finder that debuted recently in Photos for Mac and iPhone.
We hope you get some good use out of this tool. Why not take it for a spin?
Everything on HyperDisk’s website was written by a human.